强化学习基础与主流算法综述(以PPO为核心)
理论
找到一个策略去最大化 奖励
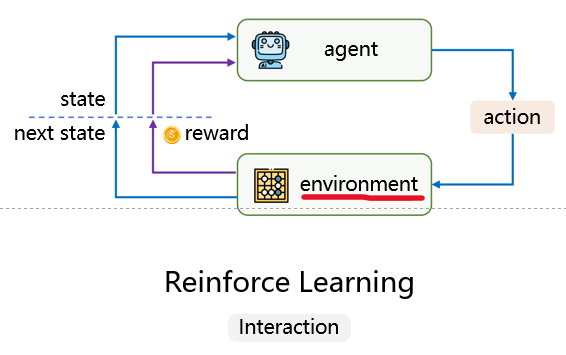
马尔科夫决策过程
小写为已发生,大写为未来

Return
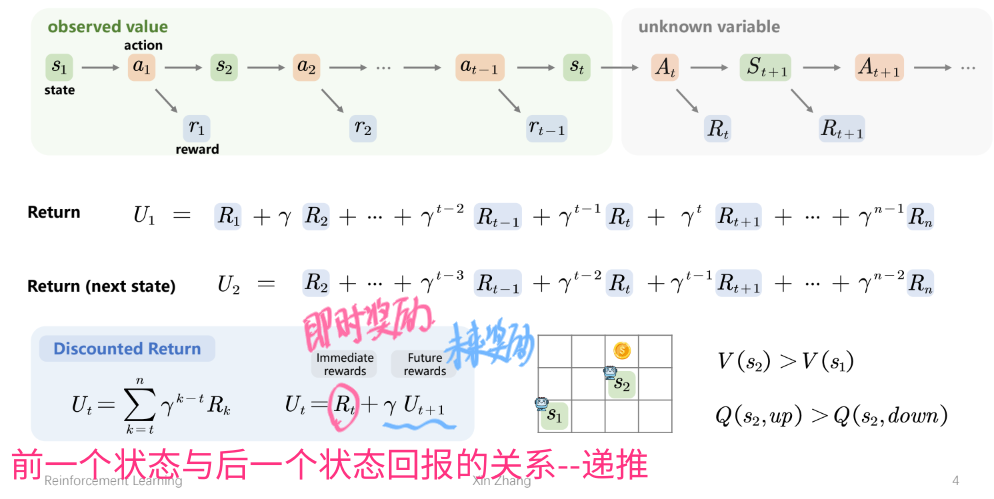
随机性与期望

Top-Down框架
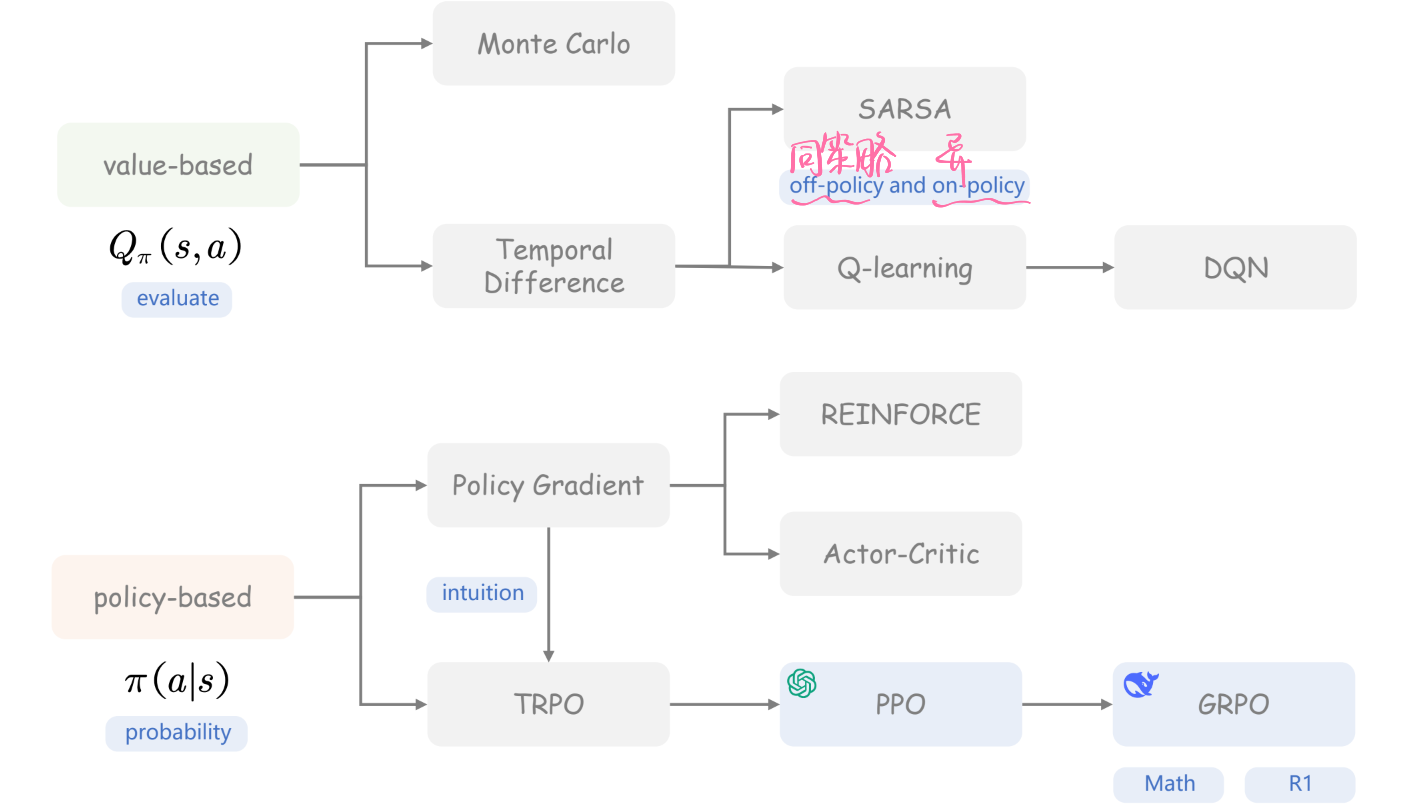
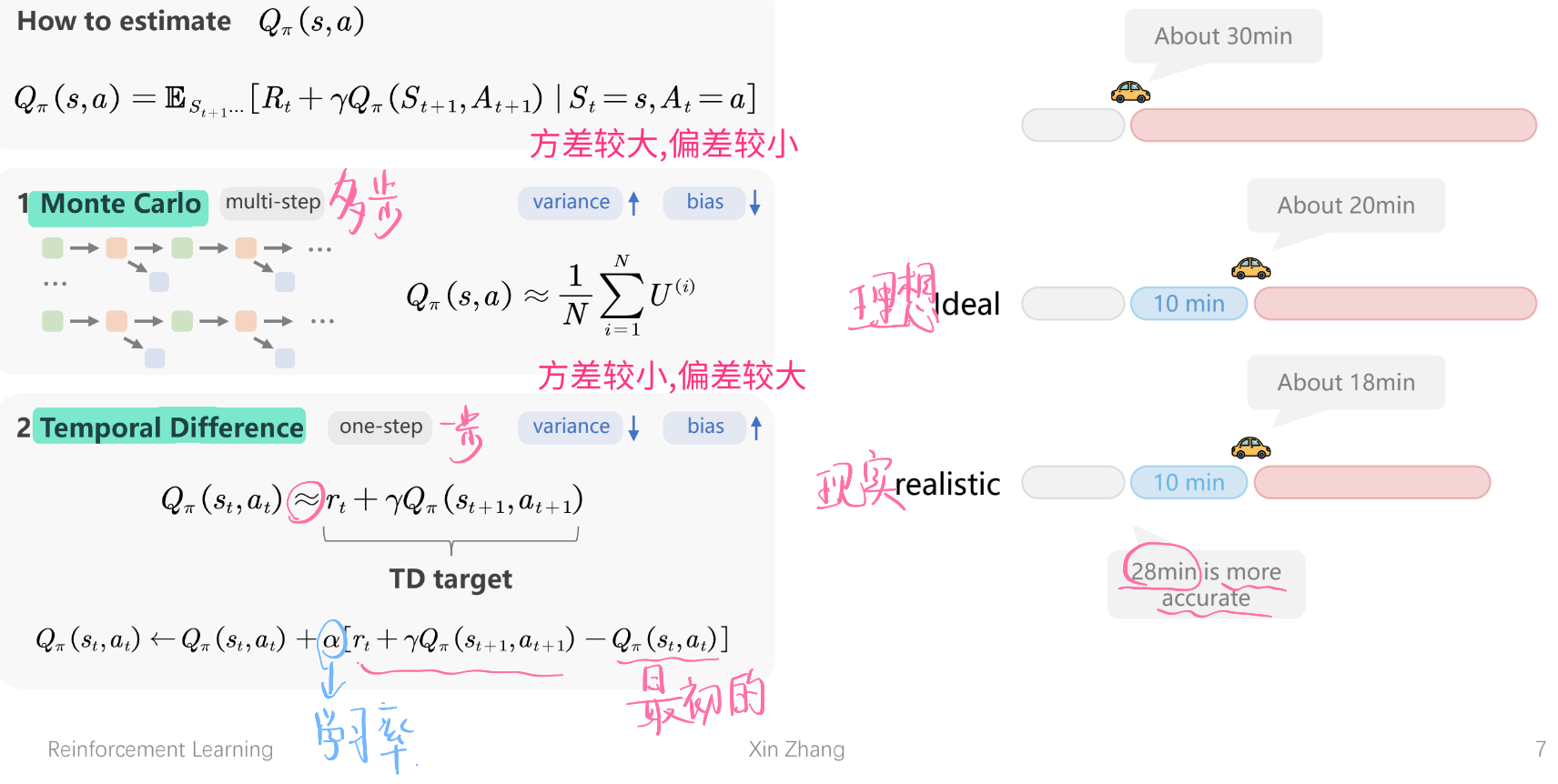
时序差分Temporal Difference (TD)
SARSA & Q-learning
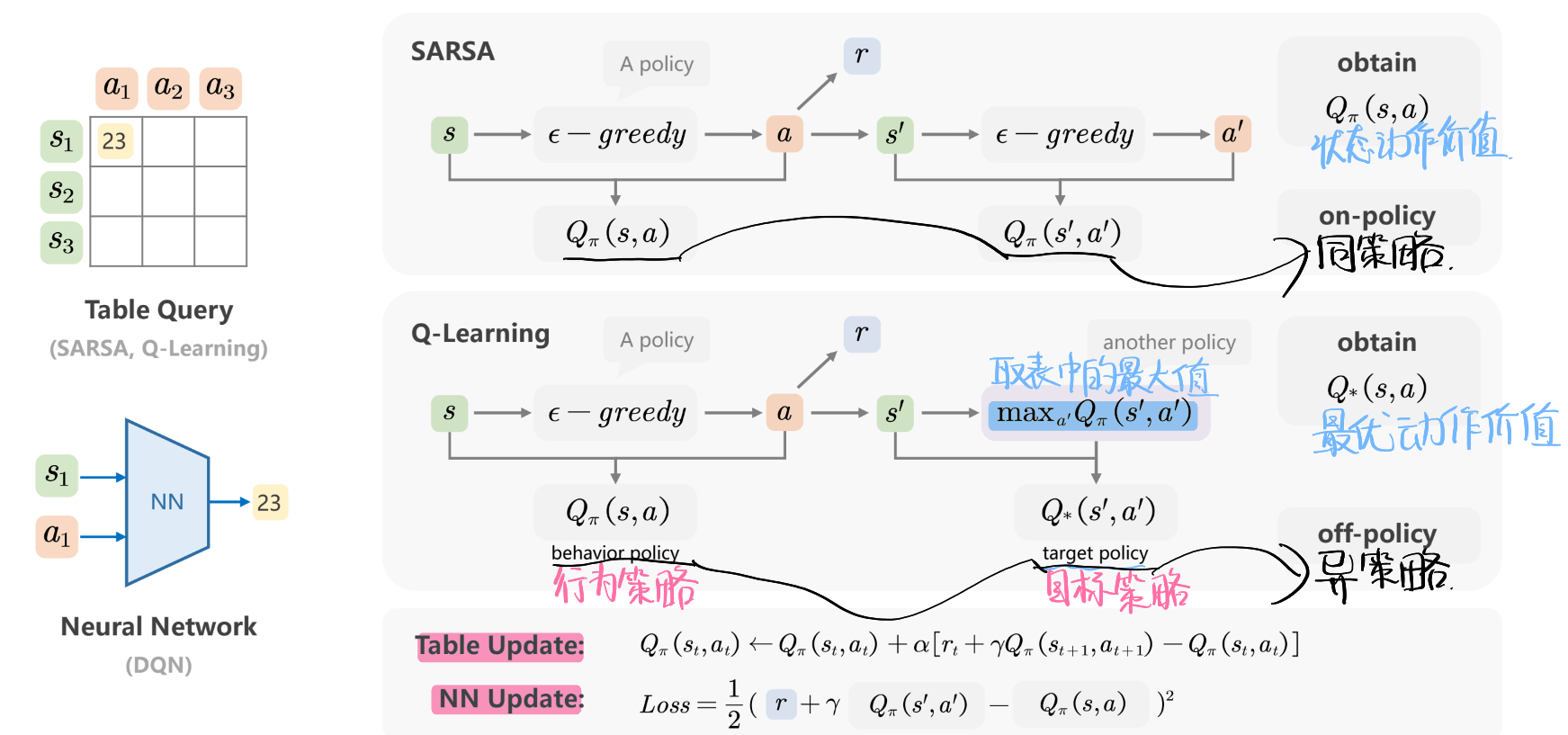
行为策略和目标策略相同为同策略,不同为异策略
Policy Gradient
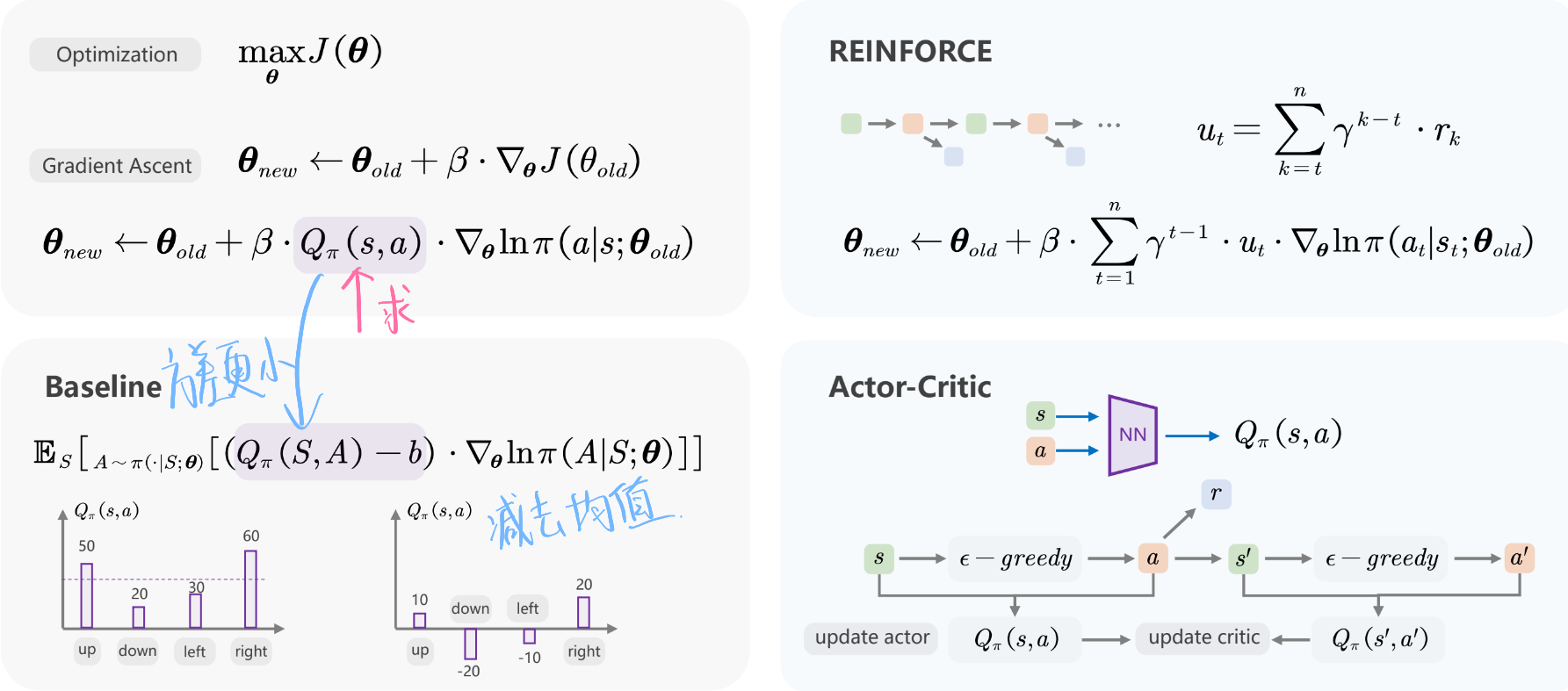
策略梯度算法🌟
策略网络
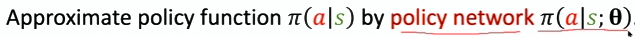



- 如何计算$q_t$ $≈$$Q_π(s_t,a_t)$?


Reinforce & Actor Critic & Baseline
存在的问题—设定学习率

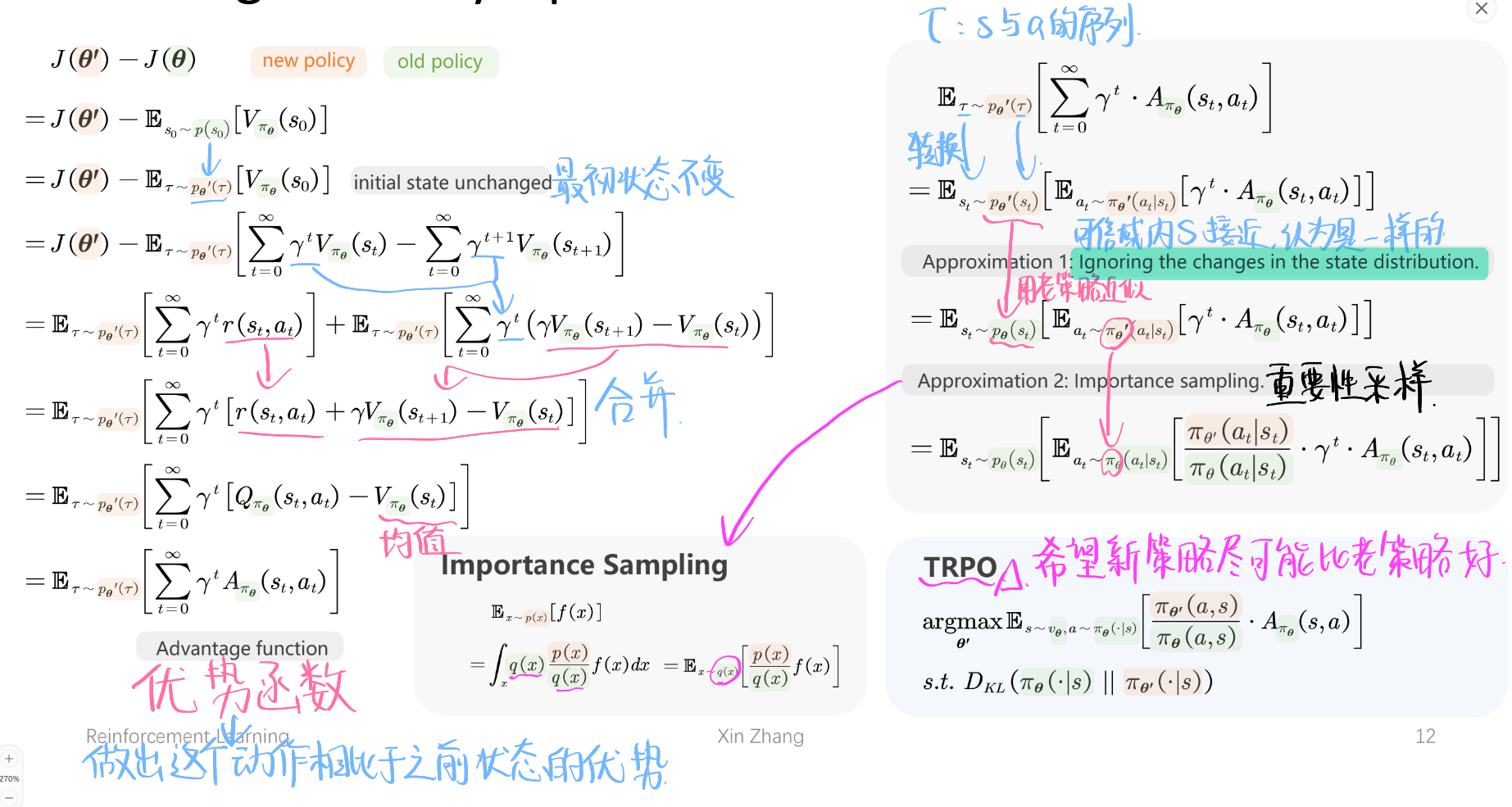
Trust Region Policy Optimization—TRPO可信域策略优化
Proximal Policy Optimization—PPO近端策略优化
改进TRPO—使求解更加方便

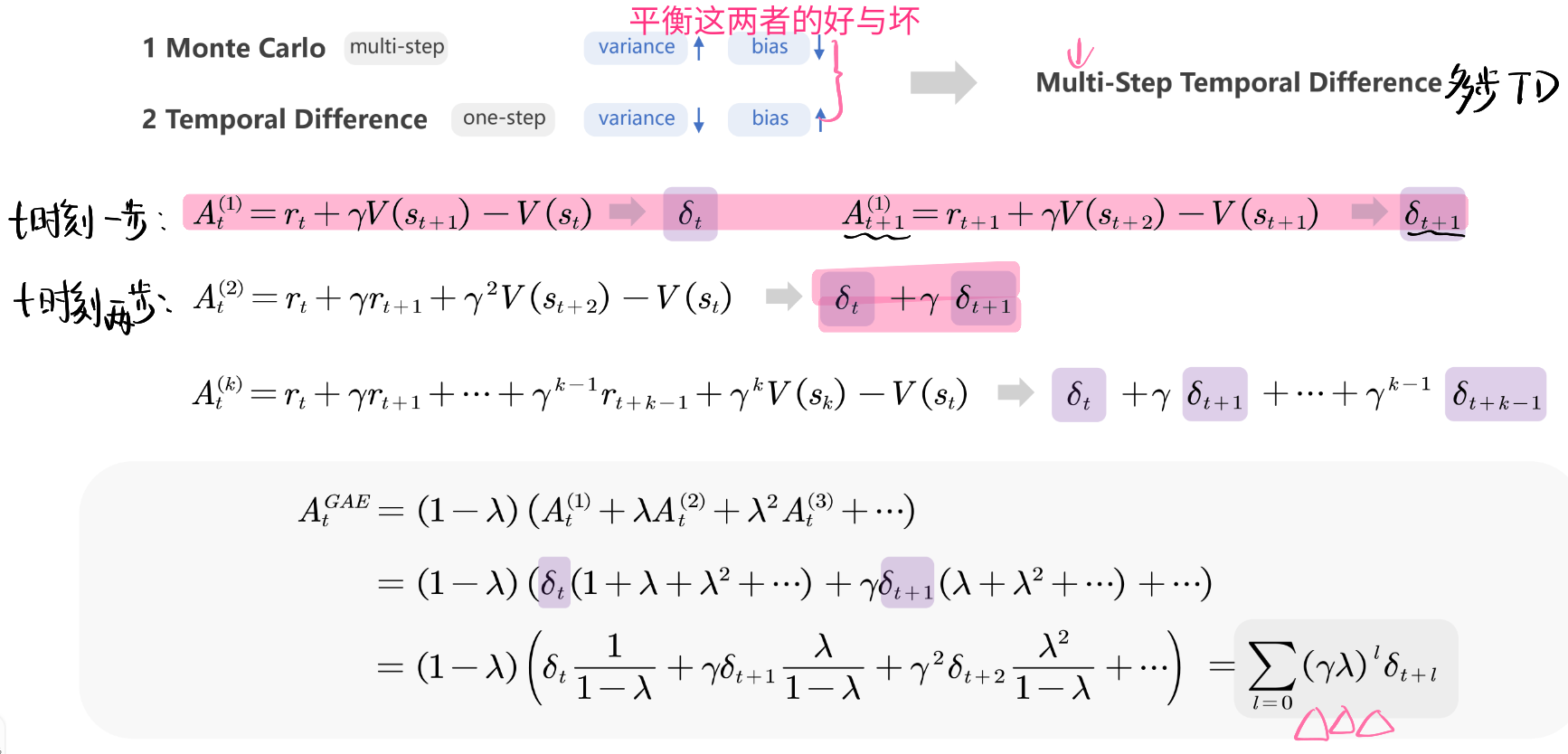
Generalized Advantage Estimation—广义优势估计—$\hat{A}$—对优势函数的改进— GAE方法
应用
PPO训练过程
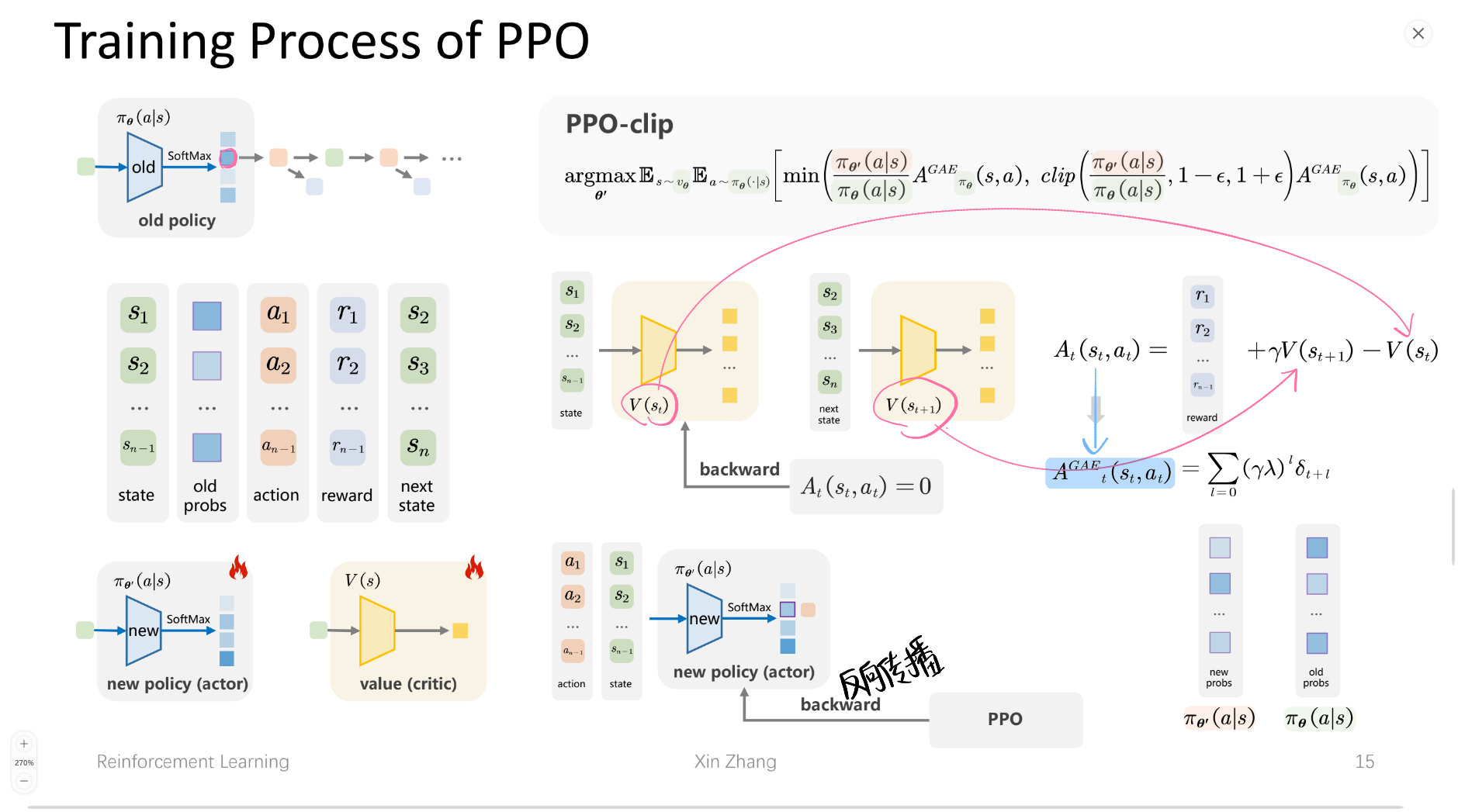

1. 数据收集阶段(左上角)
- 使用当前的旧策略(old policy)与环境交互
- 收集一系列的状态-动作-奖励序列:$(s₁,a₁,r₁), (s₂,a₂,r₂), …, (sₙ,aₙ,rₙ)$
- 这些数据构成了训练的经验池
2. 优势函数计算(右侧部分)
- 计算每个状态-动作对的优势函数 A(s,a)
- 优势函数衡量在当前状态下选择某个动作相比平均水平的好坏程度
- 公式:$Aₜ(sₜ,aₜ) = rₜ + γV(sₜ₊₁) - V(sₜ)$
- 使用GAE(Generalized Advantage Estimation)**来减少方差
3. PPO核心机制(中心公式)
PPO的关键创新是概率比例裁剪:
-
计算新旧策略的概率比例:$rₜ(θ) = πθ(aₜ sₜ)/πθ_old(aₜ sₜ)$ - 使用clip函数将比例限制在 $[1-ε, 1+ε]$ 范围内
- 目标函数:$min(rₜ(θ)Âₜ, clip(rₜ(θ), 1-ε, 1+ε)Âₜ)$
4. 网络更新
- Actor网络(策略网络):根据PPO目标函数更新参数,输出动作概率分布
- Critic网络(价值网络):通过最小化价值函数预测误差来更新,估计状态价值V(s)
5. 训练循环
整个过程不断迭代:收集数据 → 计算优势 → 更新网络 → 收集新数据…
PPO的核心优势
- 稳定性:裁剪机制防止策略更新幅度过大,避免性能崩塌
- 样本效率:可以对同一批数据进行多次更新
- 实现简单:相比TRPO等方法,PPO实现更简单高效
- 通用性:适用于连续和离散动作空间
LLM
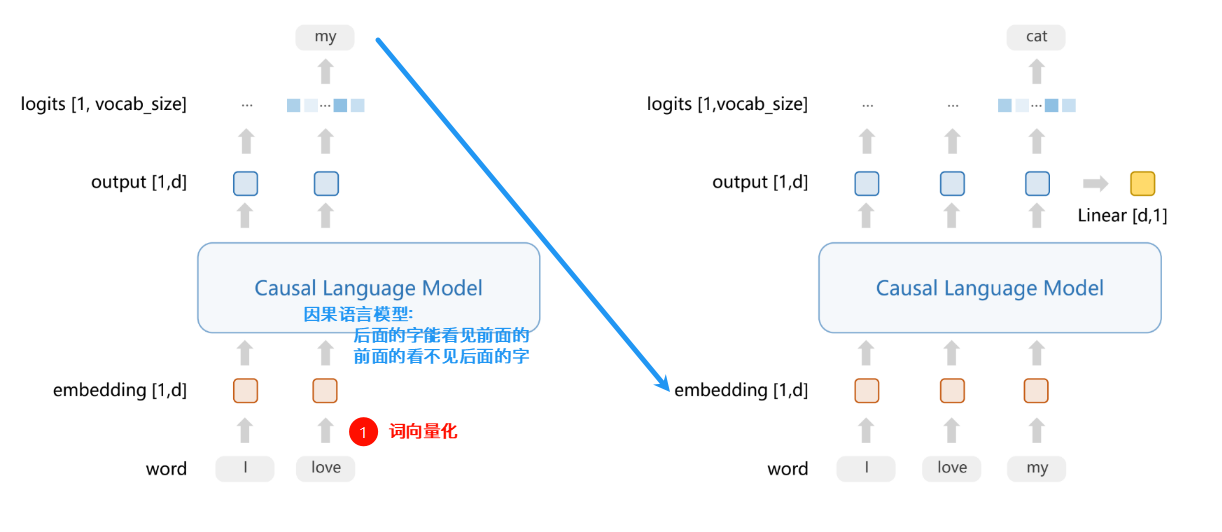
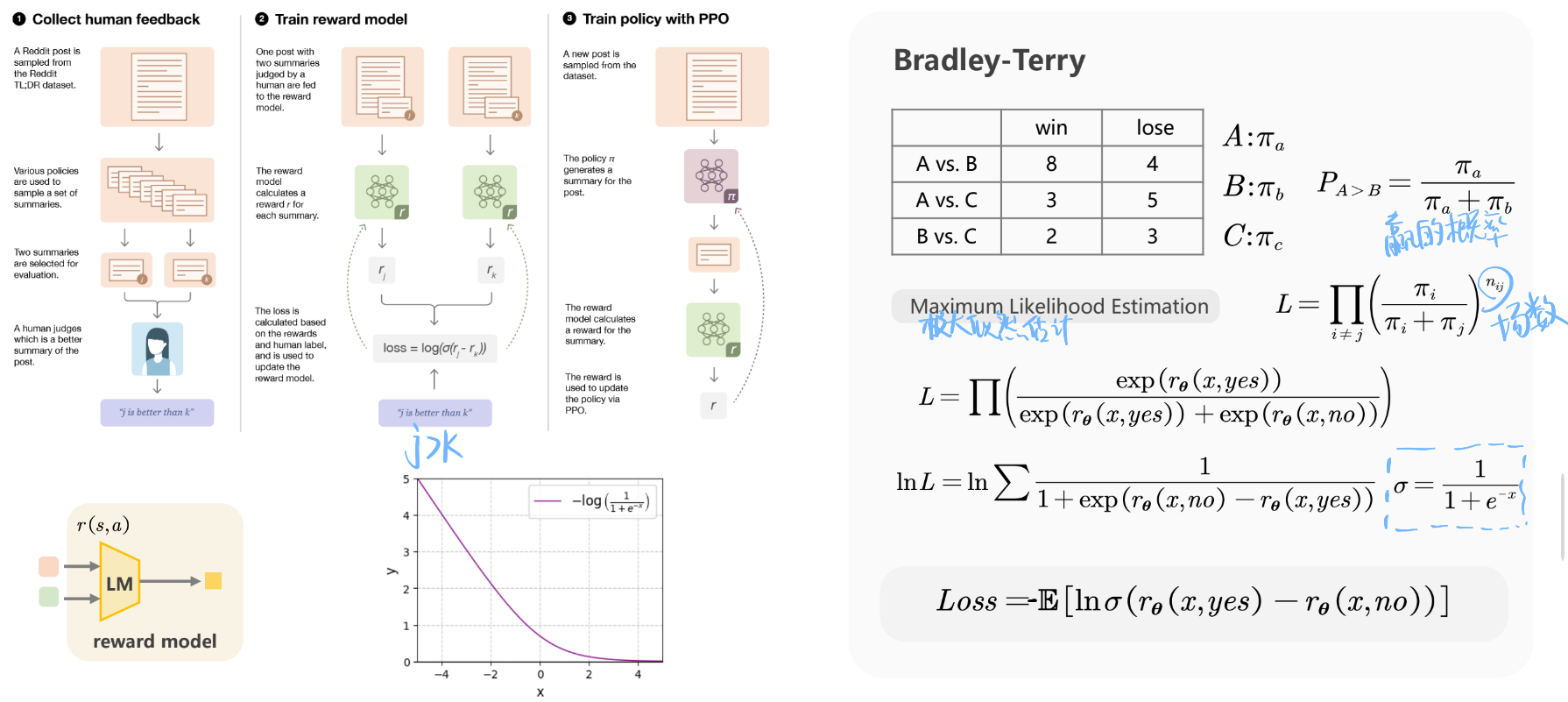
如何训练一个奖励模型?
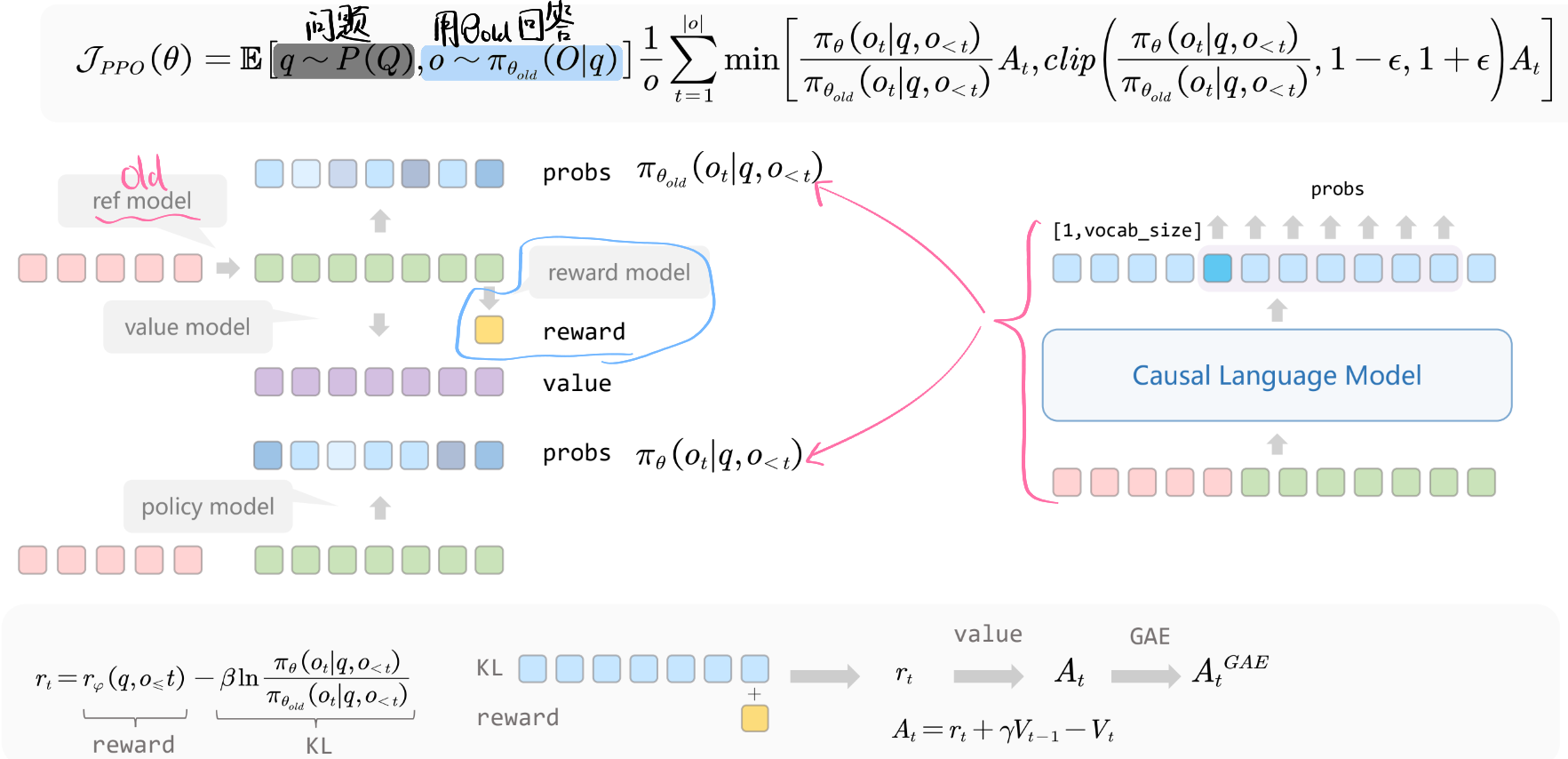
在LLM中的PPO训练过程
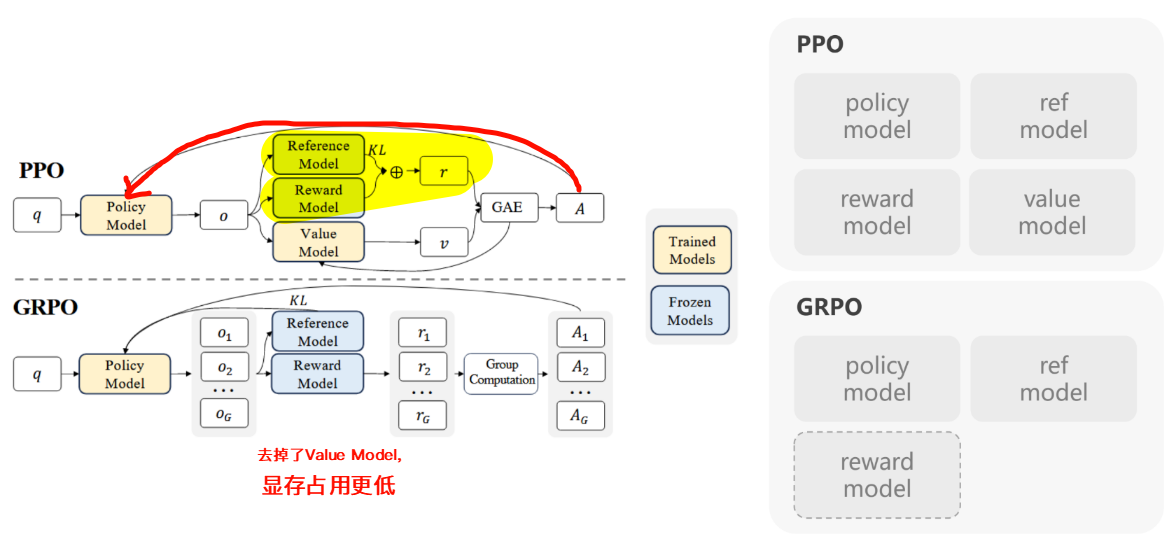
Group Relative Policy Optimization—GRPO

对比PPO&GRPO