王树森_强化学习
专业术语
马尔可夫决策过程(Markov decision process,MDP)
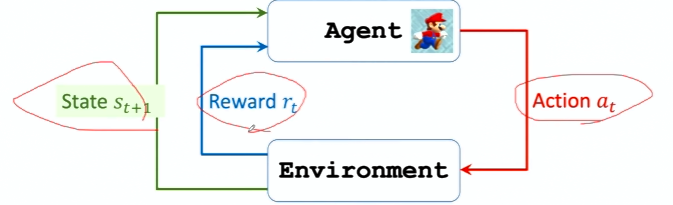
化学习的主体被称为智能体 (agent)
环境(environment)是与智能体交互的对象
每个时刻,环境有一个状态 (state),可以理解为对当前时刻环境的概括
- 棋盘上所有棋子的位置就是状态
- 一个玩家屏幕上的画面只是对环境的部分观测,画面不是对当前环境完整的概括
状态空间(state space)是指所有可能存在状态的集合,记作花体字母 $S$
- 状态空间可以是离散的,也可以是连续的
- 可以是有限集合,也可以是无限可数集合
- 超级玛丽、星际争霸、无人驾驶这些例子中,状态空间是无限集合,存在无穷多种可能的状态
- 围棋、五子棋、中国象棋这些游戏中,状态空间是离散有限集合,可以枚举出所有可能存在的状态
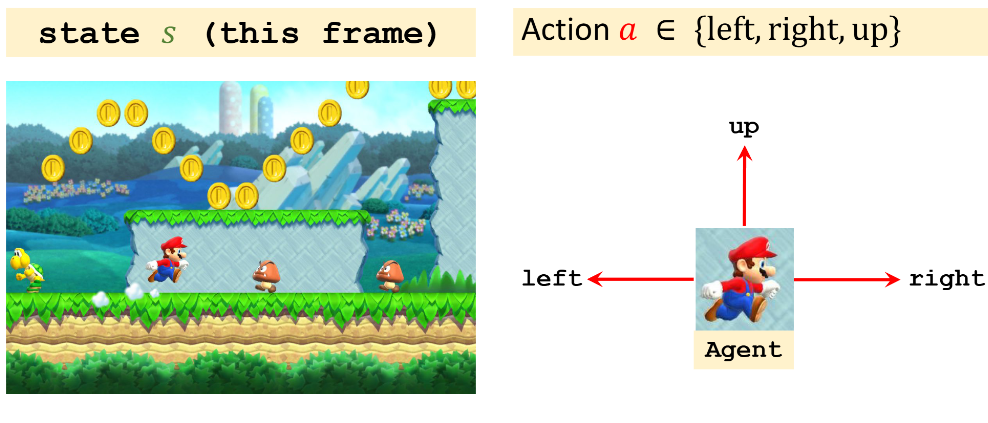
动作(action)是智能体基于当前状态所做出的决策
动作空间(action space)是指所有可能动作的集合,记作花体字母 $A$
- 在超级玛丽例子中,动作空间是 A = {左, 右, 上}。在围棋例子中,动作空间是 A = {1, 2, 3, · · · , 361}
奖励(reward)是指在智能体执行一个动作之后,环境返回给智能体的一个数值
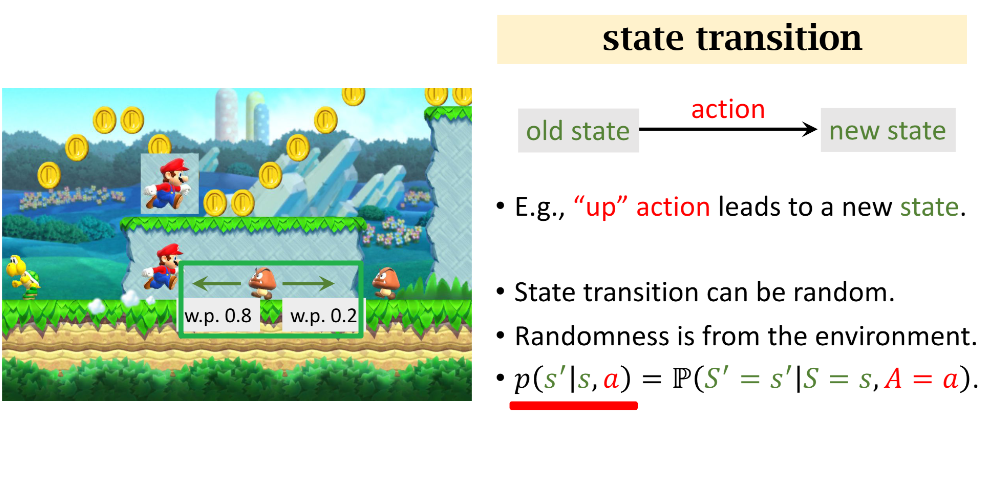
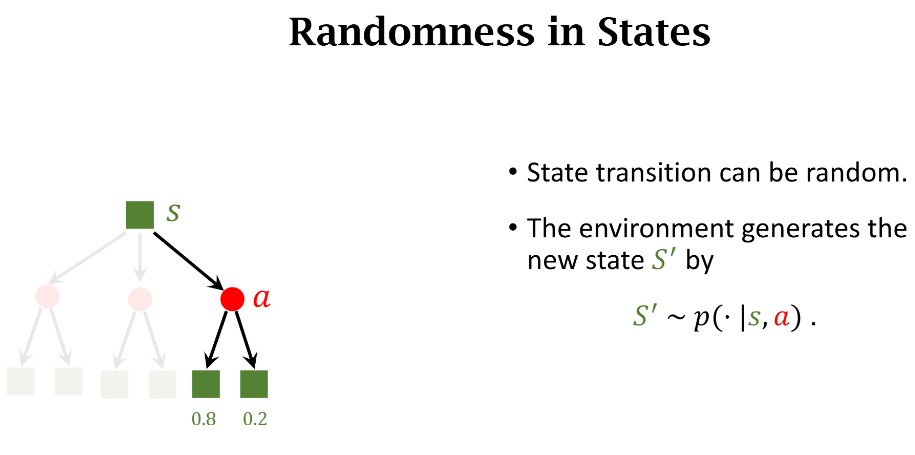
状态转移(state transition)是指智能体从当前 t 时刻的状态 s 转移到下一个时刻状态为 s′的过程
- 强化学习通常假设状态转移是随机的,随机性来自于环境
State & Action
Policy
根据观测到的状态作出决策
策略是智能体用来根据当前状态决定采取何种动作的战略 。强化学习的主要目标是找到最优策略 。
随机策略 (π(a∣s)): 这种策略为给定状态下的每个可能动作提供一个概率 。然后,智能体从这个概率分布中抽样选择其下一个动作 。 确定策略 (μ(s)): 对于任何给定的状态,该策略直接输出一个单一、具体的动作 。

Reward
使获得的奖励综合最高

State Transition
表示这个事件的概率:在当前状态 s,智能体执行动作 a,环境的状态变成 s′。
Environment Interaction
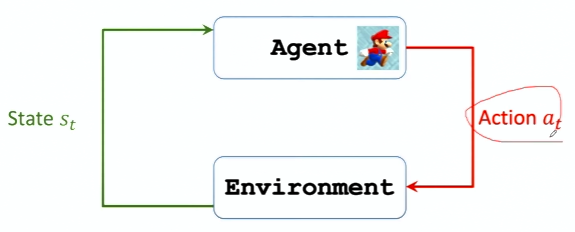
Agent做出动作后,环境会更新状态,给Agent一个奖励
两种随机性来源
强化学习中的随机性主要来自两个方面:
- 智能体的策略: 如果智能体采用随机策略,其动作选择本身就是随机的 。
- 环境的动态: 环境的状态转移可能是随机的,这意味着即使在固定的状态和动作下,产生的下一个状态也并非确定无疑 。

Agent的动作

状态转移
环境根据状态转移函数来随机抽样
Play game using AI
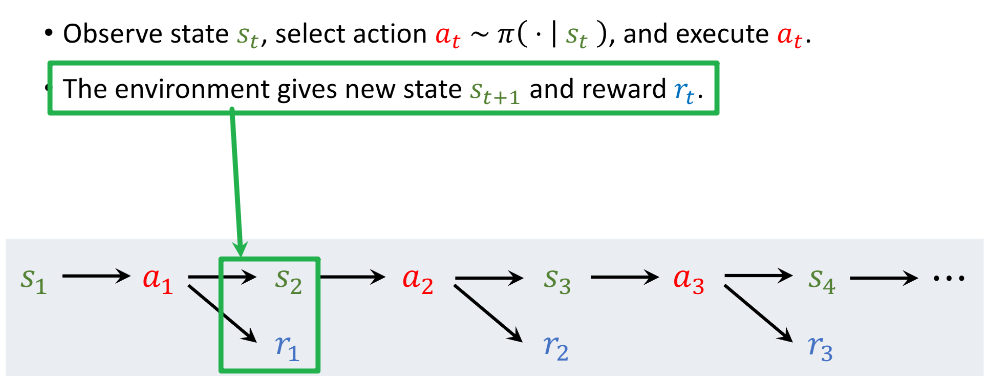
轨迹 trajectory

Rewards and Returns
在一个回合完成之前,回报 Ut 是一个随机变量,因为它取决于未来未知的状态和动作
Returns(回报)~(Cumulative future reward)(未来的累计奖励)
智能体的目标是最大化其长期的累积奖励,而不仅仅是即时奖励 。这个长期的累积奖励被称为回报。
回报: 从给定的时间步 t 开始,直到该回合结束的所有未来奖励的总和 $Ut=Rt+Rt+1+Rt+2+⋯+Rn$

Discounted Return(折扣回报)
折扣率 γ (其中 0≤γ≤1)

价值函数

动作价值函数—有助于衡量在特定状态下采取特定动作的好坏
Ut为回报
Ut中的随机性来自于 t + 1 时刻起的所有的状态和动作:
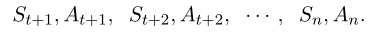
对随机变量Ut求期望,


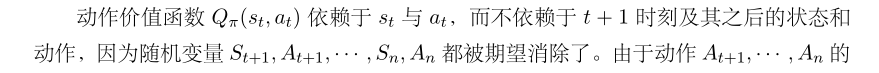
由于动作 At+1, · · · , An的 概率质量函数都是 π,公式 (3.1) 中的期望依赖于 π;用不同的 π,求期望得出的结果就会不同,因此 Qπ(st, at) 依赖于 π,


最优动作价值函数
怎么样才能排除掉策略 π 的影响,只评价当前状态和动作的好坏呢?对Qπ求MAX
该函数给出了在状态 s 中采取动作 a 后,通过遵循最优策略所能获得的最大期望回报

状态价值函数

两种方式控制Agent Play Games


强化学习智能体分类
- 基于模型的强化学习—给定模型的情况
- 策略(和/或)价值函数
- 环境模型
- 比如:上述迷宫游戏,围棋等
- 模型无关的强化学习—几乎不可能知道模型的真实情况,真正的与环境交互
- 策略(和/或)价值函数
- 没有环境模型
- 比如:Atari游戏的通用策略
价值学习
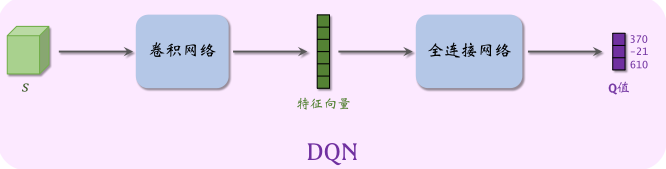
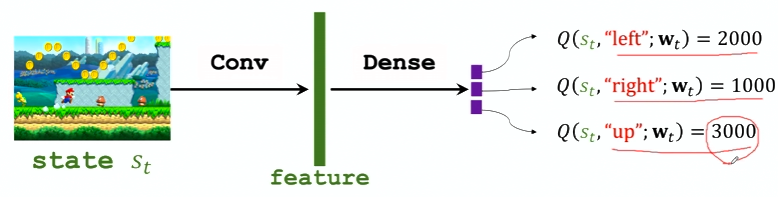
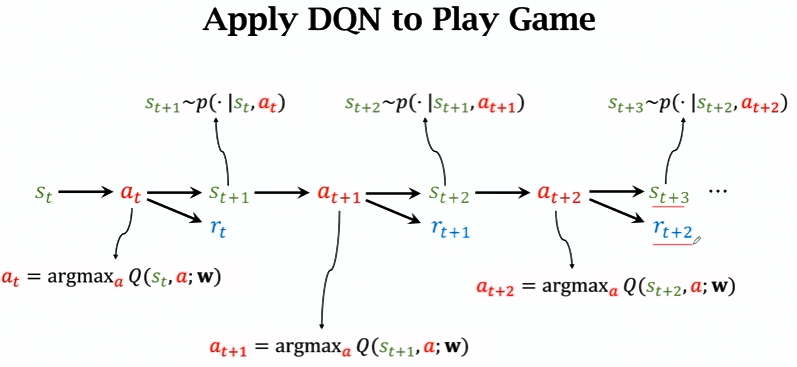
DQN

最优动作价值函数的近似: 在实践中,近似学习“先知”Q⋆最有效的办法是深度 Q网络(deep Q network,缩写 DQN),记作 Q(s, a; w)
其中的 w 表示神经网络中的参数。首先随机初始化 w,随后用“经验”去学习 w。
关于变量 w 自动求梯度,得到的梯度的形状与 w 完全相同。

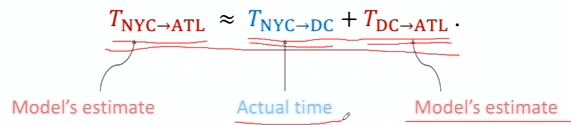
时间差分(TD)算法
开车的例子

TD算法
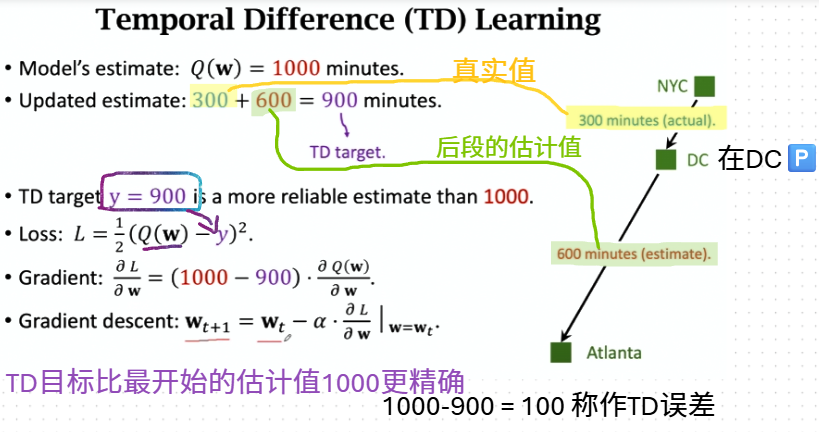
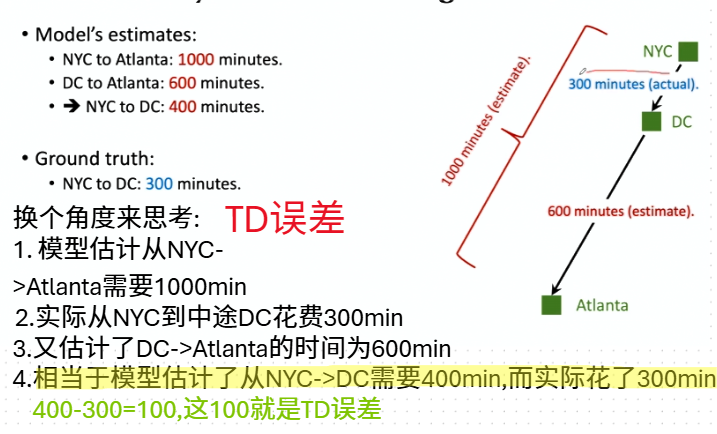
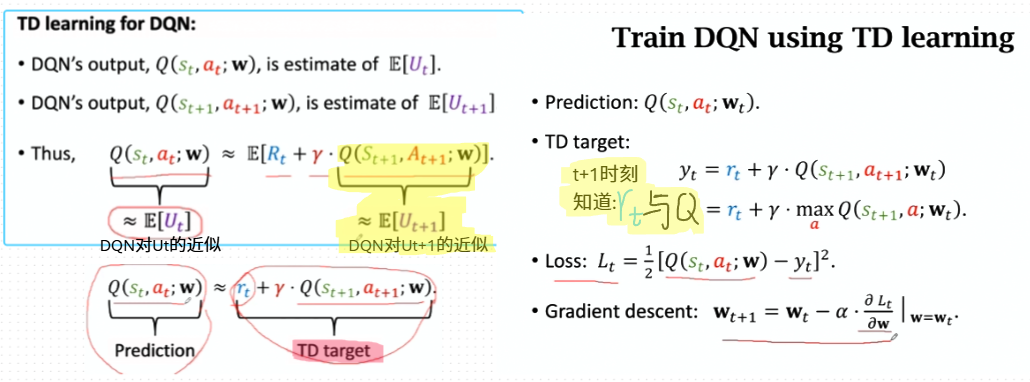
用TD训练DQN

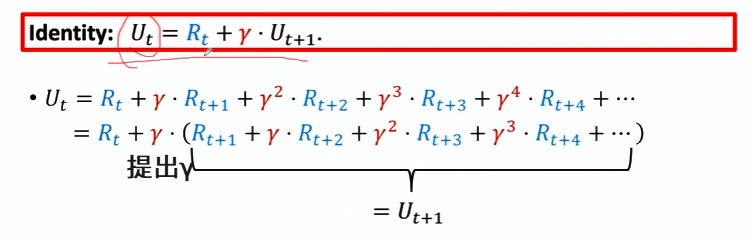

同策略 (On-policy) 与异策略 (Off-policy)
让智能体与环境交互,记录下观测到的状态、动作、奖励,用这些经验来学习一个策略函数。控制智能体与环境交互的策略被称作行为策略。
行为策略的作用是收集经验(experience),即观测的状态、动作、奖励。
强化学习的目的是得到一个策略函数,用这个策略函数来控制智能体。这个策略函数就叫做目标策略。
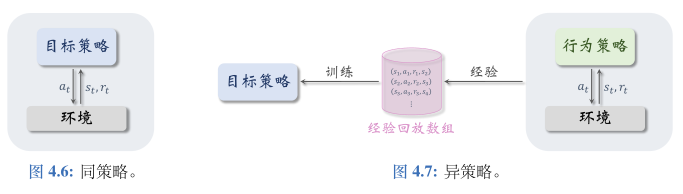
异策略的好处是可以用行为策略收集经验,把 (st, at, rt, st+1) 这样的四元组记录到一个数组里,在事后反复利用这些经验去更新目标策略。这个数组被称作经验回放数组(replay buffer),这种训练方式被称作经验回放(experience replay)。
经验回放只适用于异策略,不适用于同策略,其原因是收集经验时用的行为策略不同于想要训练出的目标策略。
Q 学习与 SARSA 的对比
- Q 学习不依赖于 π,因此 Q 学习属于异策略(off-policy),可以用经验回放。
- Q 学习的目标是学到表格 ˜Q,作为最优动作价值函数 Q⋆的近似。因为 Q⋆与 π 无关,所以在理想情况下,不论收集经验用的行为策略 π 是什么,都不影响 Q 学习得到的最优动作价值函数。因此,Q 学习属于异策略(off-policy),允许行为策略区别于目标策略。
- 而 SARSA 依赖于 π,因此 SARSA 属于同策略(on-policy),不能用经验回放。
- SARSA 算法的目标是学到表格 q,作为动作价值函数 Qπ的近似。Qπ与一个策略 π相对应,用不同的策略 π,对应 Qπ就会不同。策略 π 越好,Qπ的值越大。
- 经验回放数组里的经验 (sj, aj, rj, sj+1) 是过时的行为策略 πold收集到的,与当前策略 πnow及其对应的价值 Qπnow对应不上。想要学习 Qπ的话,必须要用与当前策略 πnow收集到的经验,而不能用过时的 πold收集到的经验。
策略学习
控制Agent运动
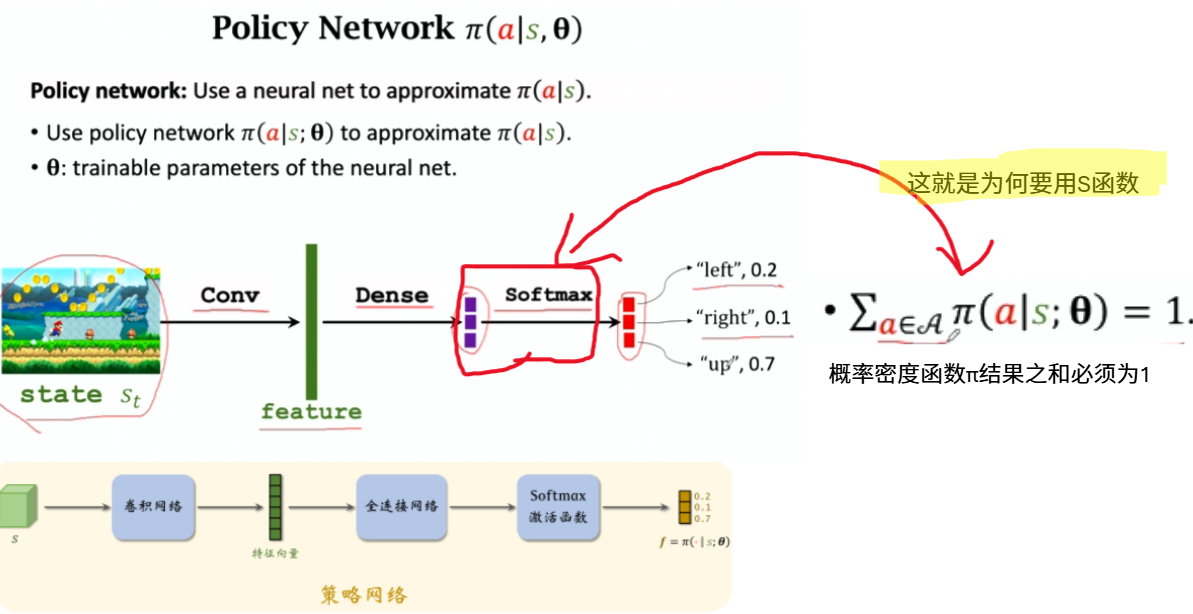
策略函数

策略网络
| 用策略神经网络 $π(a | s; θ)$ 近似策略函数 $π(a | s)$ |
状态-价值函数


策略学习Policy-Based RL

目标是改进θ,使J or V最大
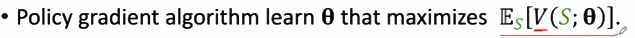
用策略梯度上升算法改进θ

策略梯度算法🌟
策略网络
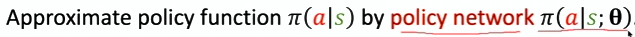



- 如何计算$q_t$ $≈$$Q_π(s_t,a_t)$?


Actor-Critic Methods
- Actor是策略网络,用来控制Agent运动—运动员
- Critic是价值网络,用来给动作打分—裁判
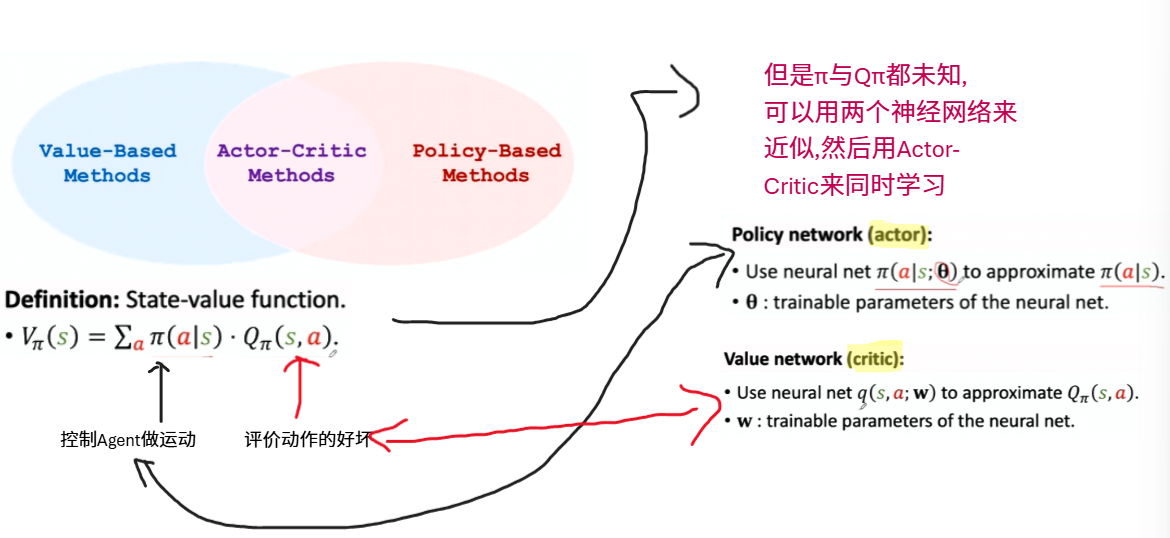

Policy Network(Actor): $\pi(a|s, \theta)$
- 输入:状态 s,例如,超级马里奥的游戏截图。
- 输出:关于动作的概率分布。
- 令 A 为所有动作的集合,例如,A={“向左”,“向右”,“向上”}。
- $∑a∈Aπ(a∣s,θ)=1$。(这就是我们使用 softmax 激活函数的原因。)

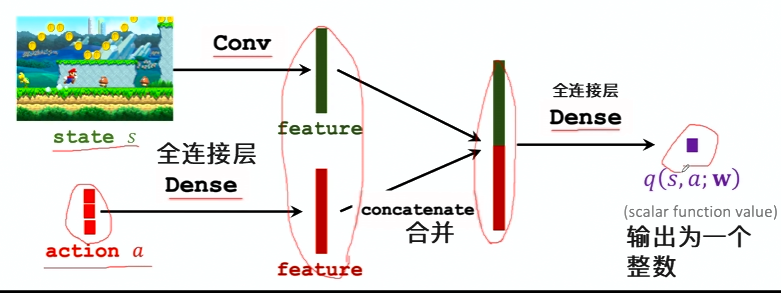
Value Network(Critic): $q(s,a;w)$
- 输入: 状态s和动作a
- 输出: 估计的动作-价值
训练
用神经网络估计状态-价值函数
- 更新策略网络 $π(a∣s;θ)$ 来提升状态价值 $V(s;θ,w)。$
- Actor (执行者) 的表现会逐渐变好。
- 其监督信号完全来自于价值网络 (Critic)
- 更新价值网络 $q(s,a;w)$ 来更准确地估计回报 $(return)。$
- Critic (评论家) 的判断会变得更准确。
- 其监督信号完全来自于奖励 (rewards)。
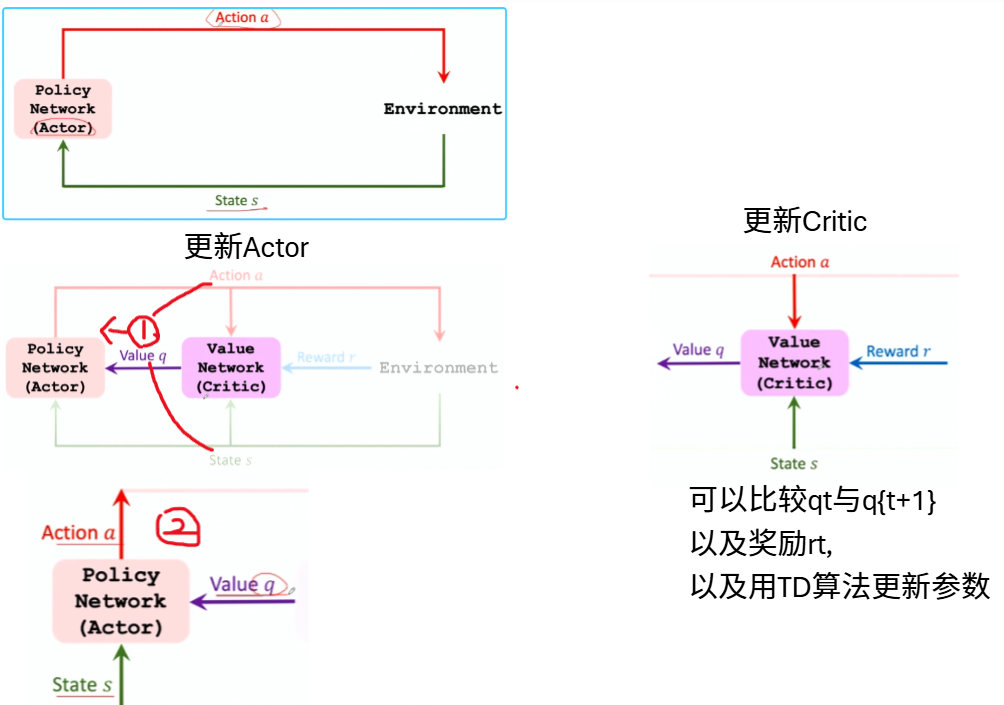
步骤: 更新参数 θ 和 w
- 观测当前状态 $s_t$。
- 根据策略 $π(⋅∣s_t;θ_t)$ 随机采样一个动作 $a_t$。
- 执行动作 $a_t$,并观测到新的状态 $s_{t+1}$ 和奖励 $r_t$。
- 使用时序差分 (Temporal Difference, TD) 的方法更新价值网络 (Value Network) 的参数 $w$,使打分更准确。
- 使用策略梯度 (Policy Gradient) 的方法更新策略网络 (Policy Network) 的参数 θ,使Agent表现更好.
用TD算法更新价值网络$q$
- 计算 $q(s_t,a_t;w_t)$ 和 $q(s_{t+1},a_{t+1};w_t)$。
-
TD 目标值 (TD target):价值网络学习的目标
$y_t = r_t + \gamma \cdot q(s_{t+1}, a_{t+1}; w_t)$
-
损失函数 (Loss):
$L(\mathbf{w}) = \frac{1}{2}[q(s_t, a_t; \mathbf{w}) - y_t]^2$
-
梯度下降 (Gradient descent):
$\mathbf{w}_{t+1} = \mathbf{w}t - \alpha \cdot \frac{\partial L(\mathbf{w})}{\partial \mathbf{w}} {\mathbf{w}=\mathbf{w}_t}$
用策略梯度算法更新策略网络π
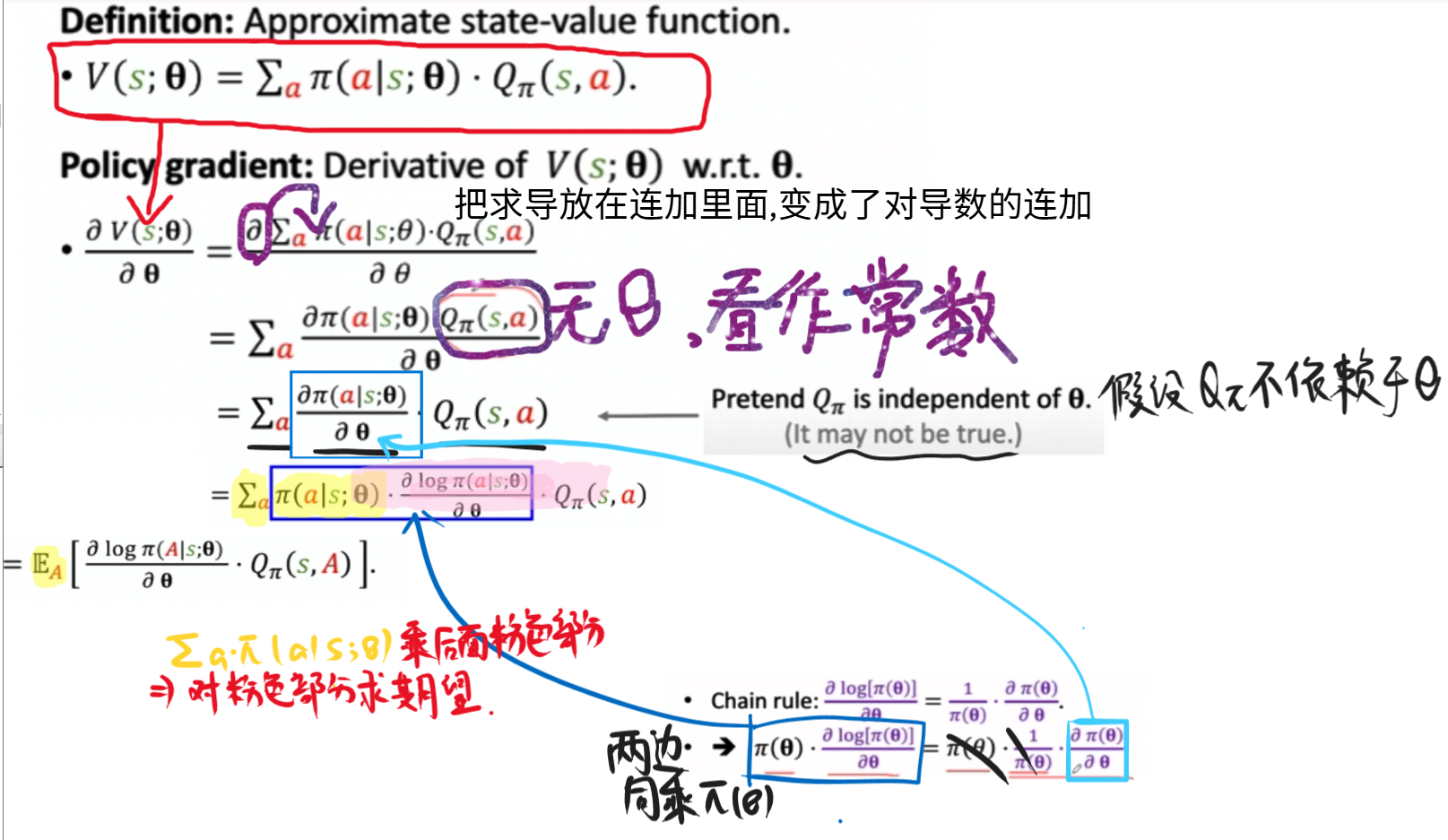
定义:使用神经网络近似的状态价值函数 (State-value function)
| $V(s; \theta, \mathbf{w}) = \sum_{a} \pi(a | s; \theta) \cdot q(s, a; \mathbf{w})$ |
策略梯度 (Policy gradient):$V(s_t;\theta,w)$ 关于 $\theta$ 的导数
-
令$\mathbf{g}(\mathbf{a}, \theta) = \frac{\partial \log \pi(\mathbf{a} s, \theta)}{\partial \theta} \cdot q(s_t, \mathbf{a}; \mathbf{w})$ -
因此,价值函数的梯度可以表示为期望的形式:
$\frac{\partial V(s; \theta, \mathbf{w}t)}{\partial \theta} = \mathbb{E}{\mathcal{A}}[\mathbf{g}(\mathbf{a}, \theta)]$
算法:使用随机策略梯度 (Stochastic Policy Gradient) 更新策略网络
- 随机采样 (Random sampling): 从当前策略中采样一个动作 $a$。$\mathbf{a} \sim \pi(\cdot | s_t; \theta_t)$(这样得到的 $g(a,\theta)$ 是真实梯度的一个无偏估计。)
- 随机梯度上升 (Stochastic gradient ascent): 使用采样得到的梯度更新策略网络的参数。$\theta_{t+1} = \theta_t + \beta \cdot \mathbf{g}(\mathbf{a}, \theta_t)$
算法总结
Actor-Critic 算法单步更新流程—每轮只执行一个动作$\tilde{a}并不执行$
- 观测与采样 观测当前状态 $s_t$,并根据当前策略 $\pi(\cdot∣s_t,\theta_t)$ 随机采样一个动作 $a_t$。$a_t∼π(⋅∣st,θt)$
- 与环境交互 执行动作 $a_t$,环境会给出新的状态 $s_{t+1}$ 和奖励 $r_t$。
-
采样下一个动作 根据当前策略(参数仍为 $\theta_t$),针对新状态 $s_{t+1}$ 采样下一个动作$\tilde{a}{t+1}$。$\tilde{a}{t+1}∼π(⋅∣s_{t+1};θ_t)$
注意: 这个动作 $\tilde{a}_{t+1}$仅用于计算,并不实际执行。
- 评估价值网络 计算当前状态-动作对的Q值 $q_t$ 和下一个状态-动作对的Q值 $q_{t+1}$。$q_t=q(s_t,a_t;w_t)和q_{t+1}=q(s_{t+1},\tilde{a}_{t+1};w_t)$
- 计算 TD 误差 (TD Error) TD 误差 $\delta_t$ 是当前Q值的估计与更准确的“TD目标值” ($r_t+\gamma.q_{t+1}$) 之间的差。$δ_t=q_t-(r_t+\gamma.q_{t+1})$
-
价值网络求导 计算价值函数关于其参数 $\mathbf{w}$ 的梯度。
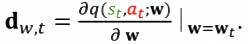
- 更新价值网络 (Critic) 使用 TD 误差和梯度来更新价值网络的参数 $\mathbf{w}$。$w_{t+1}=w_t−α⋅δ_t⋅d_{w,t}$
-
策略网络求导 计算对数策略函数关于其参数 $\theta$ 的梯度。
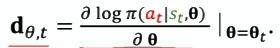
-
更新策略网络 (Actor) 使用当前Q值 $q_t$ 作为权重,更新策略网络的参数 $\theta$。这是一个梯度上升步骤,目的是让能获得更高Q值的动作出现的概率更大。
$θ_{t+1}=θ_t+β⋅q_t⋅d_{θ,t}$——标准
$θ_{t+1}=θ_t+β⋅δ_t⋅d_{θ,t}$——Baseline
训练之后
价值网络只是作为裁判帮助学习,最终目标是使Agent做出最优的动作+
Actor与Critic的更新
学习过程:更新策略网络 (Actor)
目标:通过策略梯度 (Policy Gradient) 方法,调整策略网络,使其能够做出更好的决策。
-
寻求提升状态价值: Actor 的目标是最大化状态价值函数 V($S;\theta,w$)。这个价值函数是通过当前策略π下所有可能动作的 Q 值 $q(S,a;w)$ 的期望来计算
$V(S; \theta, \mathbf{w}) = \sum_{a} \pi(a S; \theta) \cdot q(S, a; \mathbf{w})$ -
计算策略梯度: 计算状态价值 V 相对于策略参数θ的梯度。这个梯度指明了参数调整的方向,沿着这个方向可以最大程度地提升状态价值。
$\frac{\partial V(S;\theta)}{\partial \theta} = \mathbb{E}_{\mathbf{A}}\left[\frac{\partial \log \pi(\mathbf{A} S, \theta)}{\partial \theta} \cdot q(S, \mathbf{A}; \mathbf{w})\right]$ -
执行梯度上升 (Gradient Ascent): 沿着计算出的梯度方向更新策略参数θ,以增加获得高回报的概率。
学习过程:更新价值网络 (Critic)
目标:通过时序差分学习 (TD Learning) 方法,让价值网络对状态-动作的评估(即 Q 值)变得更准确。
-
预测的动作价值 (Predicted Action-Value): 对于在状态 $S_t$ 下执行的动作 $a_t$,价值网络给出一个 Q 值的预测。
$q_t = q(S_t, a_t; \mathbf{w})$
-
TD 目标值 (TD Target): 这是一个更可靠的价值目标,由实际获得的奖励 $r_t$ 和对下一个状态-动作价值的估计$q(S_{t+1}, a_{t+1}; \mathbf{w})$组成。
$y_t = r_t + \gamma \cdot q(S_{t+1}, a_{t+1}; \mathbf{w})$
-
计算梯度: 计算损失函数(即预测值 $q_t$ 和目标值 $y_t$ 之间的均方误差)相对于价值网络参数$w$的梯度。
$\frac{\partial (q_t - y_t)^2/2}{\partial \mathbf{w}} = (q_t - y_t) \cdot \frac{\partial q(S_t, a_t; \mathbf{w})}{\partial \mathbf{w}}$
-
执行梯度下降 (Gradient Descent): 沿着计算出的梯度方向更新价值参数 $\mathbf{w}$,以最小化预测值和目标值之间的误差。
AlphaGo&Model-Based RL
蒙特卡洛算法
计算π
假设有n个点均匀的分布在正方形的面积内,期望:$Pn = πn/4$
大数定律:当n→∞,实际在圆内的m个点≈ 期望$πn/4$→$m≈πn/4$→$π≈4*m/n$

近似求积分
求一元函数定积分

多元函数定积分

近似期望

期望
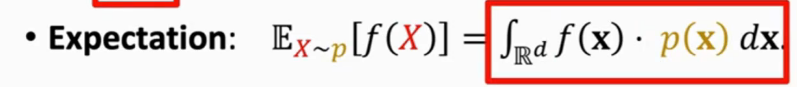

是V函数对神经网络参数θ的导数